외부 API가 의도한 대로 동작을 안 해요 (1) - ONNX Simplifier
Motivation
올해 초부터 저희 팀은 LLM이나 Stable Diffusion과 같은 대규모 모델을 경량화하는 작업을 시작했는데요. 저희는 대규모 모델을 실제 하드웨어에 배포하기까지의 스텝 중 앞부분인 Quantization Simulation을 주로 담당하고 있었습니다. Simulation이 끝난 이후 실제 하드웨어에 배포하기 위해서는 여러 가지 추가적인 과정(Compile, Optimization, ...)이 필요한데요. 저희는 이 과정을 다른 팀이 제공하는 API를 호출하는 구조로 테스트하고 있습니다. 외부 API를 호출하고 난 결과를 테스트나 시각화했을 때 이상한 점이 발견됐는데요. Transformer 기반의 모델을, API를 호출해서 결과를 받으면 Transformer의 전형적인 구조인 Q, K, V가 없어지는 현상이 발생했습니다. 저희는 여러 가지 이유로 Attention 블록 안의 Query, Key, Value를 유지해야 할 이유가 있었기 때문에 아주 난감한 상황이었는데요. 이번 포스트와 다음 포스트에서 원인에 대한 분석과 어떻게 해결했는지 시리즈로 연재를 해보려고 합니다.
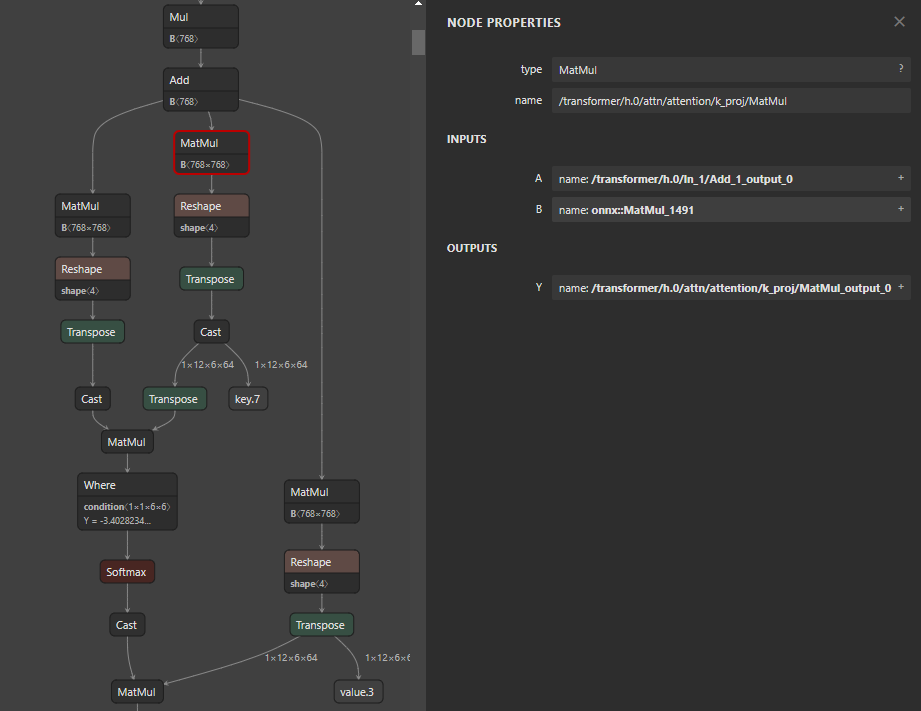

위쪽은 원본 모델을 ONNX export만 했을 때의 시각화 결과이고, 아래쪽은 외부 라이브러리 API를 호출하고 받아온 모델의 시각화 결과입니다. 기존의 768x768 Q, K, V가 오른쪽 그림에서는 768x2304로 뭔가 변경이 되면서 사라졌음을 확인할 수 있습니다. 저희는 외부 API에 대한 수정 권한은 없지만 읽기 권한은 있었기 때문에 디버깅을 통해 onnxsim.simplify를 호출한 이후에 이런 현상이 발생한다는 것까지는 확인할 수 있었습니다
이 과정을 간략화한 코드로 표현하면 아래와 같습니다.
호출자의 로직
import third_party
model = ToyModel() # Q, K, V를 가지고 있는 전형적인 Transformers 구조 모델
prepared_model = third_party.prepare_model(model)
# prepared_model은 Q, K, V 구조가 없어짐외부 API의 로직
# third_party.py
from torch import nn
import onnxsim
def prepare_model(model: nn.Module):
# Do pre-processing logic
onnx_model = torch.onnx.export(model, ...)
simplified_model, check = onnxsim.simplify(onnx_model)
# Do post-processing logic
return simplified_modelONNX
ONNX Simplifier 얘기를 하기 전에 간단하게 ONNX에 대해서 얘기를 하고 넘어가는 것이 이해에 도움이 될 것 같습니다
ONNX is an open format built to represent machine learning models.
우리가 흔히 사용하는 PyTorch나 TensorFlow는 내부적으로 모델을 표현하기 위한 graph representation을 가지고 있는데요. 아무래도 서로 다른 프레임워크다보니 그래프 구성이나 각 노드의 kernel 동작들이 다른 경우가 많습니다. 우리는 서로 다른 프레임워크의 graph representation을 ONNX의 format을 통해서 일관성 있게 표현할 수 있기를 기대합니다. 거기다 ONNX로 변환하게 되면 일종의 free lunch로 여러 가지 최적화를 수행할 수 있게 되는데요. 아래와 같은 간단한 최적화와 특정 하드웨어에 따라 추가적인 최적화 역시 제공합니다
- Constant Folding: 상수의 경우 런타임이 아니라 사전에 초기화 후 사용
- Redundant node eliminations: Identity나 Dropout처럼 추론 시 불필요한 노드를 그래프에서 제거
- Semantics-preserving node fusions: 2개 이상의 노드 (e.g., Conv-BN)을 fusion하여 메모리 액세스 횟수를 개선
이 글에서 다루고자 하는 내용은 ONNX 자체가 아니므로 좀 더 자세한 내용은 공식 문서를 참고하세요!
ONNX Simplifier
ONNX Simplifier는 ONNX Optimizer를 쓰기 쉽게 래핑한 라이브러리입니다. 디버깅을 통해서 ONNX Simplifier를 호출 하기 전/후로 그래프의 형태가 변경되었다는 것을 알고 있는 상태였기 때문에 Simplifier의 동작을 좀 더 살펴봐야 했습니다
usage: onnxsim [-h] [--enable-fuse-bn] [--skip-fuse-bn] [--skip-optimization [SKIP_OPTIMIZATION [SKIP_OPTIMIZATION ...]]] [--skip-constant-folding] [--input-shape INPUT_SHAPE [INPUT_SHAPE ...]]
[--overwrite-input-shape OVERWRITE_INPUT_SHAPE [OVERWRITE_INPUT_SHAPE ...]] [--test-input-shape TEST_INPUT_SHAPE [TEST_INPUT_SHAPE ...]] [--skip-optimizer SKIP_OPTIMIZER [SKIP_OPTIMIZER ...]]
[--skip-shape-inference] [--enable-onnxruntime-optimization] [--dynamic-input-shape] [--input-data-path INPUT_DATA_PATH [INPUT_DATA_PATH ...]] [--custom-lib CUSTOM_LIB] [--include-subgraph]
[--unused-output UNUSED_OUTPUT [UNUSED_OUTPUT ...]] [--no-large-tensor [TENSOR_SIZE_THRESHOLD]] [--mutable-initializer] [--save-as-external-data] [-v]
input_model output_model [check_n]위는 onnxsim --help의 출력값인데요. 여러 가지 인자들 중 가장 의심스러운 부분이 --skip-optimization 옵션이었습니다. 실제 Python API의 형태는 아래와 같았습니다
def simplify(
model: Union[str, onnx.ModelProto],
check_n: int = 0,
perform_optimization: bool = True,
skip_fuse_bn: bool = False,
overwrite_input_shapes=None,
test_input_shapes=None,
skipped_optimizers: Optional[List[str]] = None,
skip_constant_folding=False,
skip_shape_inference=False,
input_data=None,
dynamic_input_shape: bool = False,
custom_lib: Optional[str] = None,
include_subgraph: bool = False,
unused_output: Optional[Sequence[str]] = None,
tensor_size_threshold: str = DEFAULT_TENSOR_SIZE_THRESHOLDHOLD,
mutable_initializer: bool = False,
*,
input_shapes=None,
) -> Tuple[onnx.ModelProto, bool]저희가 호출하는 API 내부처럼 단순히 onnxsim.simplify(model) 이라면 skipped_optimizers는 기본적으로 None이라는 것까지 확인했습니다. 따라서 simplify 호출의 흐름과 skipped_optimizers를 좀 더 살펴보기로 했습니다
ONNX Simplifier 호출 로직
메인 simplify 로직은 다음과 같이 실행됩니다
def simplify(
model: Union[str, onnx.ModelProto],
skipped_optimizers: Optional[List[str]] = None,
# 다른 인자는 생략
) -> Tuple[onnx.ModelProto, bool]:
# 전처리 로직 생략
try:
model_bytes = model.SerializeToString()
model_opt_bytes = C.simplify(
model_bytes,
skipped_optimizers,
not skip_constant_folding,
not skip_shape_inference,
tensor_size_threshold,
)
# 후처리 로직 생략
except ValueError:
print("[bold magenta]Simplified model larger than 2GB. Trying to save as external data...[/bold magenta]")
# 예외 처리 로직 생략메인 함수인 simplify는 여러 가지 전처리 로직을 제외하면 다시 C.simplify를 호출하여 skipped_optimizers를 넘겨주고 있습니다. 다시 C.simplify의 구현을 살펴보면 pybind11 이용해서 C++ 호출인 Simplify(model, skip_optimizers, ...) 래핑하고 있습니다. 조금만 더 파고들면 곧 결과가 나올 것 같네요 :)
PYBIND11_MODULE(onnxsim_cpp2py_export, m) {
m.doc() = "ONNX Simplifier";
m.def("simplify",
[](const py::bytes& model_proto_bytes,
std::optional<std::vector<std::string>> skip_optimizers,
bool constant_folding, bool shape_inference,
size_t tensor_size_threshold) -> py::bytes {
// force env initialization to register opset
InitEnv();
ONNX_NAMESPACE::ModelProto model;
ParseProtoFromPyBytes(&model, model_proto_bytes);
auto const result = Simplify(model, skip_optimizers, constant_folding,
shape_inference, tensor_size_threshold);
std::string out;
result.SerializeToString(&out);
return py::bytes(out);
})
.def("simplify_path",
# 이하 생략
}onnxsim.cpp 구현을 보니 드디어 힌트를 찾을 수 있을 것 같습니다. skip_optimizers가 비어있는 vector가 아니라면 onnx::optimization::GetFuseAndEliminationPass() 모든 가능한 passes를 가져온 후 skip_optimizers로 넘겨준 최적화 pass와 일치하는 경우에만 config로 등록을 하고 있네요! 따라서 우리는 onnx::optimization::GetFuseAndEliminationPass() 이것을 확인하면 이제 skipped_optimizers를 어떻게 설정하면 되는 지 쉽게 알 수 있을 것 같습니다
#include "onnxoptimizer/optimize.h"
onnx::ModelProto Simplify(
const onnx::ModelProto& model,
std::optional<std::vector<std::string>> skip_optimizers,
bool constant_folding, bool shape_inference, size_t tensor_size_threshold) {
Check(model);
config.tensor_size_threshold = tensor_size_threshold;
config.optimizer_passes.clear();
// skip_optimizers == nullopt means skiping all optimizers, so
// config.optimizer_passes is empty
if (skip_optimizers) {
std::vector<std::string> passes;
const auto all_passes = onnx::optimization::GetFuseAndEliminationPass();
for (const auto& pass : all_passes) {
if (std::find(skip_optimizers->begin(), skip_optimizers->end(), pass) ==
skip_optimizers->end()) {
passes.push_back(pass);
}
}
config.optimizer_passes = passes;
}
// 중간 로직 생략
return sim_model;
}해당 코드는 ONNX simplifier가 아니라 ONNX optimizer에서 찾을 수 있습니다. pass_registry.cc에서 GetFuseAndEliminationPass() 구현을 찾을 수 있고 결국 pass_names를 순회하고 있는 것을 확인할 수 있었습니다
const std::vector<std::string> GlobalPassRegistry::GetFuseAndEliminationPass() {
std::vector<std::string> names;
for (const auto& name : this->pass_names) {
const auto pass_type = this->passes.at(name)->getPassType();
if (pass_type == PassType::Fuse || pass_type == PassType::Nop) {
names.push_back(name);
}
}
return names;
}GlobalPassRegistry를 살펴보면 지원할 수 있는 여러 가지 최적화 pass들이 있는데 FuseQKV가 가장 의심스러워 보입니다. 아래의 registerPass를 살펴보면 각 pass의 getPassName()을 호출하여 pass_names에 등록하고 있네요!
namespace ONNX_NAMESPACE {
namespace optimization {
// Registry containing all passes available in ONNX.
struct GlobalPassRegistry {
std::map<std::string, std::shared_ptr<Pass>> passes;
std::vector<std::string> pass_names;
GlobalPassRegistry() {
// Register the optimization passes to the optimizer.
registerPass<AdjustAdd>();
// ...
registerPass<FuseQKV>();
// ...
registerPass<RewriteInputDtype>();
}
// 중략
const std::vector<std::string> GetAvailablePasses() {
return pass_names;
}
const std::vector<std::string> GetFuseAndEliminationPass();
template <typename T>
void registerPass() {
static_assert(std::is_base_of<Pass, T>::value, "T must inherit from Pass");
std::shared_ptr<Pass> pass(new T());
passes[pass->getPassName()] = pass;
pass_names.emplace_back(pass->getPassName());
}
};
} // namespace optimization
} // namespace ONNX_NAMESPACE마지막으로 FuseQKV의 구현을 살펴보면 이제 문제를 해결할 수 있을 것 같습니다. GetPassName()으로 "fuse_qkv"를 반환하고 있네요
struct FuseQKV final : public PredicateBasedPass {
explicit FuseQKV()
: PredicateBasedPass(PassType::Fuse, PassEfficiency::Complete,
PassOptimizationType::Compute) {}
std::string getPassName() const override {
return "fuse_qkv";
}특정 ONNX Optimizer의 pass 이름을 알고 있다면, Simplifier에서 특정 최적화는 실행하지 않게 할 수 있을 것 같습니다. 한 가지 팁을 드리자면, ONNX Optimizer의 pass 파일의 확장자를 뺀 문자열이 최적화 이름과 동일하게 됩니다. 예를 들어, identity 노드를 제거하기 싫다면 eliminate_identity.h에서 확장자를 뺀 eliminate_identity를 skipped_optimizers로 전달하면 됩니다. 제 경우, qkv의 fusion을 비활성화하고 싶으므로 skipped_optimizers=["fuse_qkv"] 를 넘겨주었습니다. 실제로 해당 결과를 살펴보겠습니다
적용 전후 결과
model_simp, check = simplify(model, skipped_optimizers=["fuse_qkv"]) 결과를 보면 원본 모델과 비교해서 Cast 노드는 최적화 이후에 사라졌지만, 여전히 Q, K, V 블록 구조는 유지되고 있는 것을 확인할 수 있습니다. 즉, 특정 최적화를 비활성화하는 데 드디어 성공했네요!
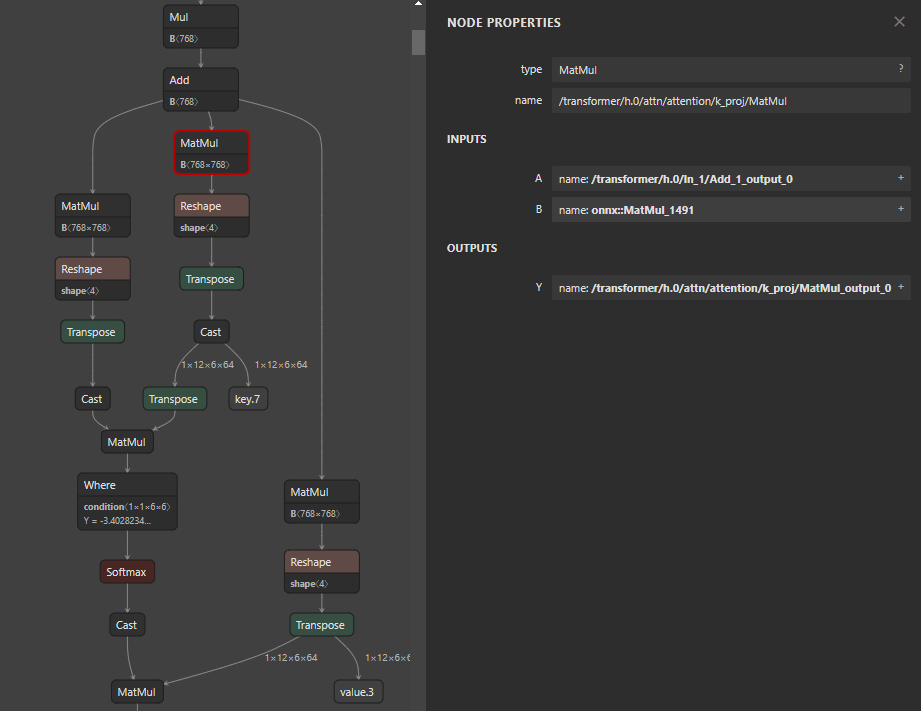
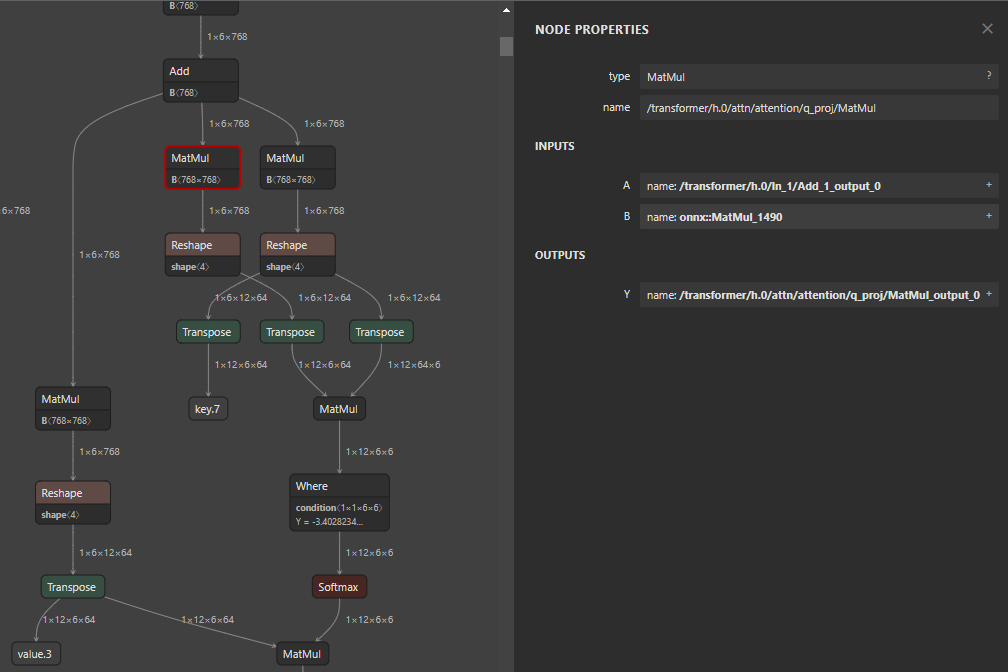
Future work
이제 어떤 부분이 원인인지는 확실하게 알았고, 제 개발 환경에서 재현도 성공했습니다. 하지만, 우리가 호출하는 API는 외부 팀에서 제공하는 것이기 때문에 저희가 직접 수정할 수가 없었는데요. 심지어 외부 팀에 skipped_optimizer를 전달할 수 있게 API 수정을 요청했지만 리소스 문제로 힘들다는 답변이 온 상태입니다. 이 경우 우리는 어떻게 이런 문제를 해결할 수 있었을까요? 다음 포스트에서는 수정 권한이 없는 호출에 대해서 onnx simplifier를 포함하여 여러 가지 문제를 해결한 방법들을 소개하겠습니다