Adapter Pattern
Adapter pattern?
여러분들은 어댑터라는 용어를 어디서 들어보셨나요? 저는 해외여행 시 필수품 중 하나인 110v 어댑터가 먼저 생각이 나는데요.

110v 어댑터는 우리가 한국에서 사용하는 220v에 디자인 되어있는 전자기기를 110v 단자에서도 사용할 수 있게 도와주는 중간 매개체 정도로 표현할 수 있을 것 같습니다. 소프트웨어 개발에서도 Adapter Pattern이라는 것이 존재하고, 위에서 얘기한 110v 어댑터와 비슷한 역할을 위해서 도와주는 하나의 디자인 패턴이라고 볼 수 있겠는데요. 여러 디자인 패턴과 마찬가지로 어댑터 패턴 역시 객체지향 설계의 여러 원칙을 준수하기 위해서, 그리고 코드의 재사용 및 유연성을 위해서 도입된 패턴입니다. 좀 더 자세한 내용은 아래에서 알아보겠습니다
Motivation
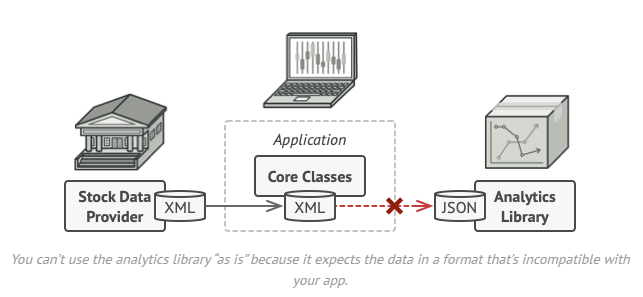
팀에서 개발하고 있는 애플리케이션은 주식시장의 데이터 (XML)을 가져와서 멋진 도표로 시각화해 주는 프로그램인데요. 거기에 더해서 여러 가지 분석을 도와줄 수 있는 기능을 추가하려는 비즈니스 요청이 있었다고 가정해 보겠습니다. 운이 나쁘게도 개발 기한에 맞추려면 우리가 스크래치부터 분석 라이브러리를 만들기에는 부족하고, 3rd party 라이브러리를 활용할 수밖에 없다는 결론이 나왔는데요. 이렇게 시간이 충분하지 않아서 외부 라이브러리를 사용해야하는 경우는 아주 흔히 발생하는 실제 소프트웨어 개발 사이클이죠? 문제는 3rd party 라이브러리가 받는 데이터의 포맷은 XML이 아니라 JSON만 가능한 상황입니다. 외부 라이브러리이므로 우리가 직접 소스코드를 수정하기도 어려운 상황인데요. 기존 코드 베이스를 크게 해치지 않으면서 이 문제를 어떻게 해결하면 좋을까요? 이럴 때 사용할 수 있는 구현 패턴이 Adapter 패턴입니다!
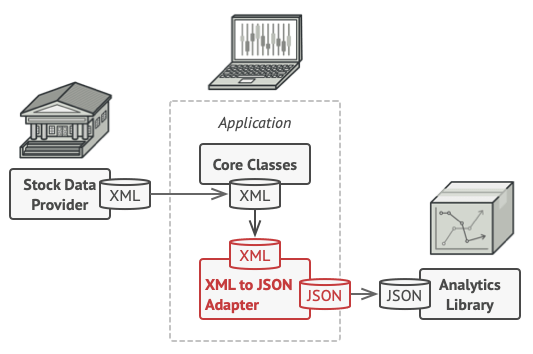
110v 어댑터처럼 XML을 JSON에 맞출 수 있는 어댑터를 구현한다면 기존에 XML을 다뤄서 처리하는 Core Class 부분과 분석용 라이브러리의 코드를 수정하지 않고, Adatper (여기서는 데이터 포매팅)이라는 하나의 책임만 담당하는 중간 블록을 이용해서 우리의 목적을 달성할 수 있을 것 같습니다. 아마 개념적으로는 크게 어렵지 않을거라고 생각하고, 어떻게 구현할 지에 대한 내용으로 넘어가보겠습니다
How to implement?
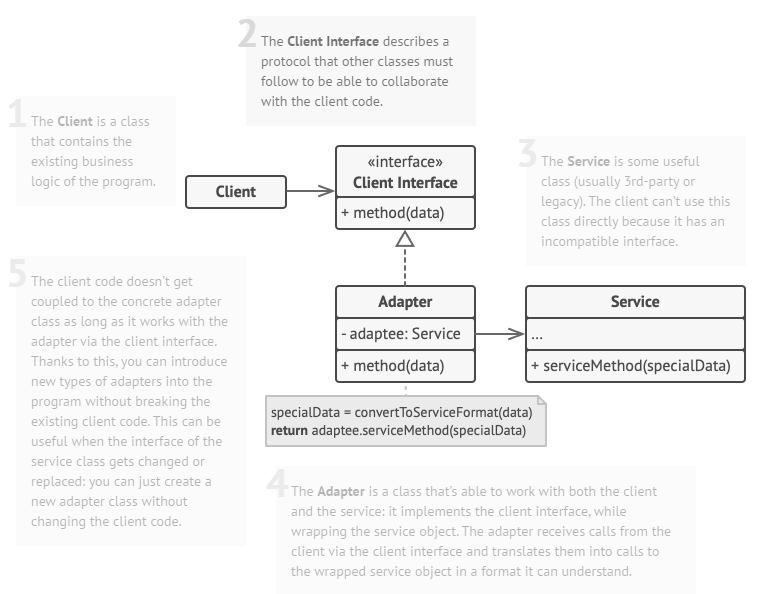
전체적인 클래스 다이어그램은 위와 같습니다. 우선 프로토콜을 정의한 클라이언트 인터페이스를 하나 만들고 해당 인터페이스를 구현한 Adatper가 존재합니다. Adapter는 대체로 외부 라이브러리와 같은 Service adaptee를 생성자 인자로 들고 있고 우리는 클라이언트 인터페이스의 메서드를 연결할 수 있는 비지니스 로직만 구현하면 Client와 Service 코드를 수정 없이 연결할 수 있습니다
다음은 refactoring.guru의 간단한 어댑터 패턴 구현 예제입니다 ( https://refactoring.guru/design-patterns/adapter/python/example#example-1 )
class Target:
"""
The Target defines the domain-specific interface used by the client code.
"""
def request(self) -> str:
return "Target: The default target's behavior."
class Adaptee:
"""
The Adaptee contains some useful behavior, but its interface is incompatible
with the existing client code. The Adaptee needs some adaptation before the
client code can use it.
"""
def specific_request(self) -> str:
return ".eetpadA eht fo roivaheb laicepS"
class Adapter(Target):
"""
The Adapter makes the Adaptee's interface compatible with the Target's
interface via composition.
"""
def __init__(self, adaptee: Adaptee) -> None:
self.adaptee = adaptee
def request(self) -> str:
return f"Adapter: (TRANSLATED) {self.adaptee.specific_request()[::-1]}"
def client_code(target: Target) -> None:
"""
The client code supports all classes that follow the Target interface.
"""
print(target.request(), end="")
if __name__ == "__main__":
print("Client: I can work just fine with the Target objects:")
target = Target()
client_code(target)
print("\n")
adaptee = Adaptee()
print("Client: The Adaptee class has a weird interface. "
"See, I don't understand it:")
print(f"Adaptee: {adaptee.specific_request()}", end="\n\n")
print("Client: But I can work with it via the Adapter:")
adapter = Adapter(adaptee)
client_code(adapter)
# Client: I can work just fine with the Target objects:
# Target: The default target's behavior.
# Client: The Adaptee class has a weird interface. See, I don't understand it:
# Adaptee: .eetpadA eht fo roivaheb laicepS
# Client: But I can work with it via the Adapter:
# Adapter: (TRANSLATED) Special behavior of the Adaptee.우리가 처음에 얘기했던 client 코드의 Target을 XML라고 생각한다면 Adaptee는 JSON이라고 생각할 수 있겠습니다
client_code가 Adaptee를 받을 수 있도록, Target을 상속한 Adapter를 만들고 호출 프로토콜인 request만 Adaptee의 로직을 적절히 수정해서 맞춰주면 되겠습니다
참 쉽죠?
Pros and cons
그러면 이런 Adapter 패턴의 장단점은 어떤 것들이 있을까요? 바로 답을 보지 마시고 잠깐 생각을 해보시면 더 좋겠습니다!
앞서 말씀드린 것처럼 Adapter를 활용하면서 비즈니스 로직을 담당하는 클라이언트와 외부 로직인 3rd-party 라이브러리를 수정하지 않고 본연의 adaptation만 집중하는 점은 Single Responsibility Principle을 위배하지 않는 것이 첫 번째 장점일 것이고 두 번째로 이런 부류의 수정은 시간이 지나면 또 변경될 수 있을 것입니다. 가령 JSON 대신 Serialized Binary를 3rd-party에서 사용한다든가 하는 변경 사항이 생길 수 있겠죠? 이 경우에도 우리는 간단하게 Adapter만 새로 만들면 쉽게 대응할 수 있으므로 확장에는 열려있는 Open-Closed Principle을 만족하는 좋은 디자인이라고 할 수 있겠습니다. 단점은 디자인을 위해서 추가적인 interface와 class를 조금 더 늘려야 한다는 것인데 얻을 수 있는 장점보다는 아주 약한 단점이라고 생각되네요 :)
Real world example
이런 Adapter 패턴은 여러 오픈소스에서도 광범위하게 찾아볼 수 있는데요. 아무래도 실제 코드로 보는 것이 더 와닿겠죠? 그중 다양한 백엔드를 지원하겠다고 발표한 Keras 3.0에서도 어댑터 패턴의 흔적을 찾아볼 수 있었습니다. Keras 3.0의 소개 문구 중 일부를 인용해 보겠습니다
Keras 3 is a full rewrite of Keras that enables you to run your Keras workflows on top of either JAX, TensorFlow, or PyTorch, and that unlocks brand new large-scale model training and deployment capabilities.
Keras로 작성한 워크플로를 여러 가지 백엔드 (Jax, TensorFlow, or PyTorch)에서 사용할 수 있다고 합니다. Machine Learning 파이프라인은 모델뿐만 아니라, 데이터 전처리나 학습/추론 파이프라인 역시 중요한데요. 아래 문구를 통해 이런 부분 역시 유연한 설계를 통해서 지원하고 있다는 점을 알 수 있습니다.
Use data pipelines from any source. The Keras 3 fit()/evaluate()/predict() routines are compatible with tf.data.Dataset objects, with PyTorch DataLoader objects, with NumPy arrays, Pandas dataframes — regardless of the backend you're using. You can train a Keras 3 + TensorFlow model on a PyTorch DataLoader or train a Keras 3 + PyTorch model on a tf.data.Dataset.
그러면 실제로 Keras 3.0에서 Adapter 패턴이 사용된 부분을 살펴보면 앞에서 얘기한 이론적인 내용이 좀 더 이해하기 좋을 것 같습니다!
class DataAdapter(object):
"""Base class for input data adapters.
The purpose of a DataAdapter is to provide a unfied interface to
iterate over input data provided in a variety of formats -- such as
NumPy arrays, tf.Tensors, tf.data.Datasets, Keras PyDatasets, etc.
"""
def get_numpy_iterator(self):
"""Get a Python iterable for the `DataAdapter`, that yields NumPy
arrays.
Returns:
A Python iterator.
"""
raise NotImplementedError
def get_tf_dataset(self):
"""Get a `tf.data.Dataset` instance for the DataAdapter.
Note that the dataset returned does not repeat for epoch, so caller
might need to create new iterator for the same dataset at the beginning
of the epoch. This behavior might change in the future.
Returns:
A `tf.data.Dataset`. Caller might use the dataset in different
context, e.g. iter(dataset) in eager to get the value directly, or
in graph mode, provide the iterator tensor to Keras model function.
"""
raise NotImplementedError
def get_jax_iterator(self):
"""Get a Python iterable for the `DataAdapter`, that yields JAX arrays.
Returns:
A Python iterator.
"""
raise NotImplementedError
def get_torch_dataloader(self):
"""Get a Torch `DataLoader` for the `DataAdapter`.
Returns:
A Torch `DataLoader`.
"""
raise NotImplementedError
# 이하 Property 관련 코드 중략DataAdapter라는 추상 클래스를 정의하고, 여러 백엔드에 대응할 수 있는 어댑터 메서드들이 눈에 띕니다. 아마도 DataAdapter를 상속받은 구상 클래스들이 이제 해당 메서드들을 구현하여, 프레임워크 agnostic하게 동작을 지원할 수 있을 거라고 예상이 되네요! 그중 하나의 예제로 TorchDataLoaderAdapter의 구현을 한 번 살펴보겠습니다
class TorchDataLoaderAdapter(DataAdapter):
"""Adapter that handles `torch.utils.data.DataLoader`."""
def __init__(self, dataloader):
import torch
if not isinstance(dataloader, torch.utils.data.DataLoader):
raise ValueError(
f"Expected argument `dataloader` to be an instance of"
f"`torch.utils.data.DataLoader`. Received: {dataloader}"
)
self._dataloader = dataloader
self._output_signature = None
self._batch_size = dataloader.batch_size
self._num_batches = None
self._partial_batch_size = None
if hasattr(dataloader.dataset, "__len__"):
self._num_batches = len(dataloader)
if self._batch_size is not None:
self._partial_batch_size = (
len(dataloader.dataset) % self._batch_size
)
def get_numpy_iterator(self):
for batch in self._dataloader:
# shared memory using `np.asarray`
yield tuple(
tree.map_structure(lambda x: np.asarray(x.cpu()), batch)
)
def get_jax_iterator(self):
# We use numpy as an intermediary because the conversion
# torch -> numpy -> jax is faster than torch -> jax.
return data_adapter_utils.get_jax_iterator(self.get_numpy_iterator())
def get_tf_dataset(self):
from keras.utils.module_utils import tensorflow as tf
if self._output_signature is None:
batches = list(
itertools.islice(
self._dataloader,
data_adapter_utils.NUM_BATCHES_FOR_TENSOR_SPEC,
)
)
self._output_signature = tuple(
data_adapter_utils.get_tensor_spec(batches)
)
return tf.data.Dataset.from_generator(
self.get_numpy_iterator,
output_signature=self._output_signature,
)
def get_torch_dataloader(self):
return self._dataloader추상 클래스인 DataAdapter를 상속받아서 필요한 메서드들을 구현하고 있는 것을 볼 수 있습니다. 생성자로는 torch의 DataLoader를 인자로 받고 있고, 이제 우리가 필요한 상황에 따라 적절히 get_numpy_iterator, get_tf_dataset 등을 호출만 하면 호출하는 클라이언트에서는 편하게 상황에 맞는 데이터 객체를 받아서 처리할 수 있겠습니다
마무리
이번 포스트에서는 디자인 패턴 중 하나인 Adapter 패턴을 알아보았는데요. 개인적으로는 실제 프로덕션 코드 개발에 있어서 매우 흔히 사용하고
아주 중요한 패턴 중 하나라고 생각합니다. 우리의 개발 요구사항은 시간이 지나면서 빠르게 변하고, 그때마다 기존의 코드를 매번 맞춰서 수정한다면 매우 괴로운 일이 될 수밖에 없을 겁니다. 그 외에 다른 팀에서 구현한 객체의 버전이 변경 (v1 -> v2)되어 우리가 호출하는 API의 수정이 생길 때에도 비지니스 로직을 변경하는 것이 아니라 어댑터 패턴을 활용하면 중간 계층을 활용하여 이런 부분을 좀 더 유연하게 대처할 수 있을 거로 생각합니다