Full Stack Optimization of Transformer Inference: a Survey (1)
최근 회사 내부 스터디에서 진행하고 발표했던 서베이 논문에 대해서 정리하려고 합니다. 서베이 논문답게 분량이 꽤 있으므로 몇 편에 나눠서 글을 작성할 계획이며, 대체로 앞에서 다루는 Transformer 구조와 백그라운드에 대해서는 잘 알고 계시는 분들이 많으므로 상대적으로 생소한 3장 Hardware Design부터 진행합니다 (다만 요청이 있거나 생각이 바뀌면 1~2장에 대해서도 추가 작성할 계획은 있습니다). 글 작성의 기본이 되는 내은 Full Stack Optimization of Transformer Inference: a Survey ( https://arxiv.org/abs/2302.14017 )이며 일부 Figure는 다른 논문에서 가져올 수 있습니다
사내에서 이 논문이 선택된 배경은 다음과 같았습니다. 대부분의 소프트웨어 엔지니어 또는 머신러닝 엔지니어들이 새로운 모델의 개발 및 구현에 집중하는 반면, 해당 모델이 동작할 하드웨어에 대해서는 배경지식이 부족하거나 상대적으로 관심이 부족하다는 점이었습니다. 제가 속한 팀 특성상 실제로 모델이 올라갈 하드웨어 및 컴파일러 조직과 긴밀한 협업이 필요했는데요. 해당 논문에서 다루고 있는 내용 중 많은 부분이 아! 예전에 알았더라면 더 좋은 의사소통되었을 부분들이 꽤 많이 있었습니다. 일반적인 서비스 개발 조직에서 하드웨어 최적화까지 신경 써야 할 일은 아직은 많지 않을 것으로 생각합니다만, 알아두면 분명히 도움이 될 내용이라고 생각하여 블로그를 통해 소개해 봅니다
일반적으로 딥러닝은 학습 (Training)과 추론(Inference)을 별개의 단계로 보고 있고, 최근 들어 대규모 LLM 또는 Vision 모델의 경우 작은 규모의 회사나 연구실에서 처음부터 학습하기는 쉽지 않아졌습니다. 따라서 LLaMA와 같이 큰 회사에서 공개하는 모델을 Fine-tuning해서 사용하는 경우가 많으며, 바꿔서 얘기하면 학습된 모델을 그대로 또는 조금 튜닝해서 사용하므로 점점 더 추론 영역에서의 최적화가 중요해질 것으로 생각할 수 있습니다. 해당 논문은 특히 최근 유행중인 Transformer 구조에서 추론을 어떻게 최적화할지에 대해서 소프트웨어/하드웨어 가리지 않고 서술하고 있습니다
HARDWARE DESIGN
각 하위 챕터로 넘어가기 전에 Deep Learning 가속기 (Accelerator)의 컴포넌트들을 먼저 살펴보고 가는 게 좋겠습니다
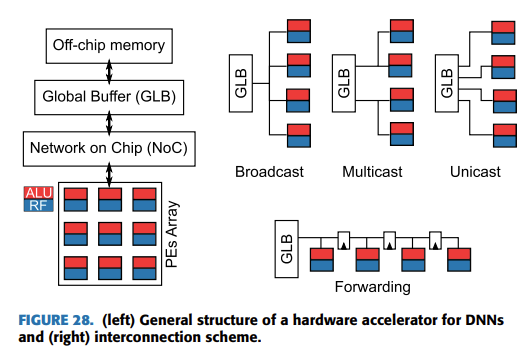
위 Figure의 왼쪽의 컴포넌트들이 키 컴포넌트들이라고 할 수 있는데요. 4개의 중요한 컴포넌트로 구성되어있다고 생각할 수 있습니다
- Off-chip DRAM: 전체 모델의 Weight와 Activation을 저장가능한 사이즈의 컴포넌트
- On-chip Memory (Global Buffer): Processing elements에 전달할 Weight와 Activation의 서브셋을 저장가능한 사이즈의 컴포넌트
- Array of PEs: 주 역할은 MAC (Multiply and Accumulation) 연산을 하는 것이며, Global Buffer에 비해 energe cost가 적은 로컬 메모리인 register file (RF)를 들고 있음
- Network-on-chip (NoC): PE들 간의 데이터 전송이나 Global Buffer에서 PE로의 데이터 분배에 대한 역할을 담당함
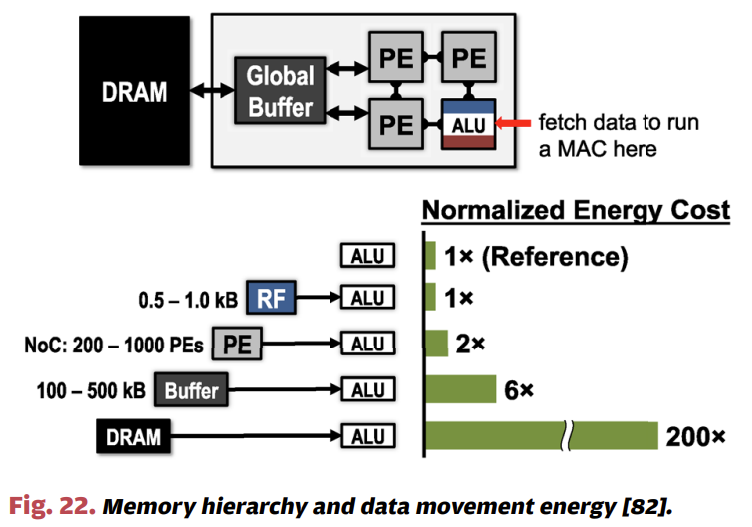
메모리면 메모리지 Off-chip Memory, Global Buffer, Register file 등 왜 이렇게 복잡한 형태로 메모리 계층을 구성하였을까요? 가장 큰 이유는 저장소마다 데이터를 전송할 때의 비용이 다르기 때문입니다. 쉽게 생각해서 연산을 담당하는 PE에서는 가장 근처의 로컬 메모리인 RF를 액세스하는 속도 및 비용이 가장 효율적이며, 상대적으로 먼 영역에 있는 DRAM은 아주 비싼 연산입니다. 위 그림과 같이 PE의 ALU를 기준으로 RF, 다른 PE, Global Buffer, 그리고 DRAM 순으로 에너지 비용이 늘어나는 것을 확인할 수 있습니다. 바꿔서 얘기하면 우리는 여러 전략을 동원하여 가능하면 이런 비싼 메모리 접근을 최대한 줄이고 재사용을 하는 방향으로 최적화를 진행해야 합니다. 재사용과 관련된 최적화는 다음 장에서 좀 더 자세히 얘기해 보겠습니다
1. Overview of Typical DNN Accelerators
앞에서 데이터의 재사용에 대해서 강조했었는데요. 데이터의 재사용은 크게 1) Temporal dataflow와 2) Spatial dataflow 2개의 범주로 얘기할 수 있습니다.
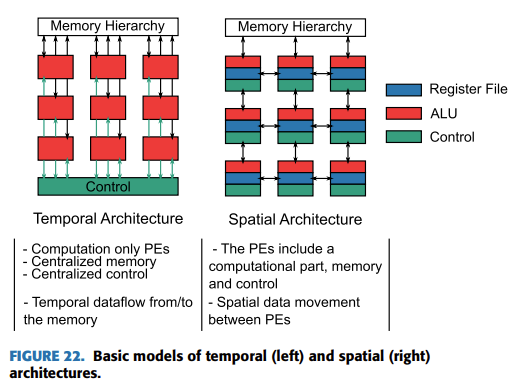
Temporal dataflow는 글로벌 버퍼에서 데이터를 가져와 PE의 ALU에서 연산을 진행하고 다시 Global Buffer로 돌아가는 구조인데요. 대표적인 예시로는 SIMD(Single Instruction Multiple Data)와 SIMT (Single Instruction Multiple Thread)가 있습니다. 즉, SIMD의 경우 Single thread가 하나의 Instruction을 여러 개의 Datapath lanes를 통해 실행하는 것을 의미하며, 대개 특수한 SIMD 레지스터를 통해 Concurrent하게 데이터 요소들이 처리되게 됩니다. Intel 진영의 AVX나 ARM의 Neon가 대표적인 예제입니다. SIMT는 SIMD의 확장판 정도로 얘기할 수 있는데요. 스레드의 그룹 (CUDA의 warp 또는 AMD의 wavefront)가 Instruction을 여러 개의 Datapath lanes를 통해 실행하는 것을 의미합니다. SIMD와 다르게 단순히 data elements가 아닌 각 스레드는 고유의 Program Counter와 Stack Pointer를 들고 있으므로 좀 더 복잡한 작업이 가능합니다. 우리가 흔히 사용하는 CUDA 프로그래밍이 SIMT의 좋은 예제라고 생각할 수 있을 것 같네요
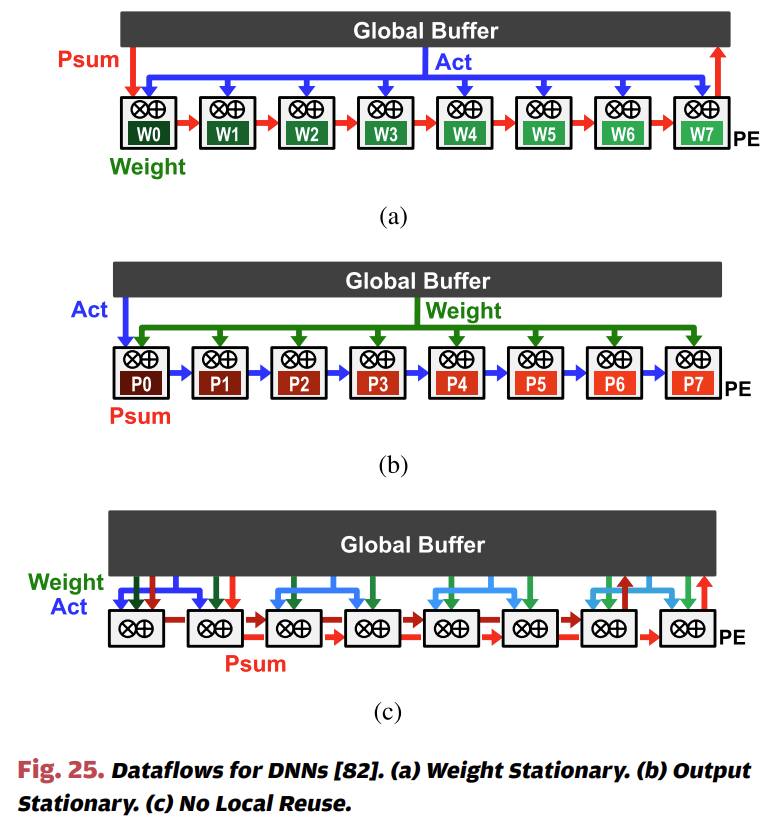
위에서 얘기한 Temproal dataflow는 하나의 Instruction을 '동시에' 처리하는 방식으로 재사용을 한다면, Spatial dataflow는 메모리 계층을 활용해서 데이터 재사용을 한다고 생각할 수 있습니다. 앞에서 얘기한 것처럼 ALU에 가까울수록 접근 비용 및 에너지 효율이 높으므로 우리는 가능하면 ALU에 가까운 곳에 재사용할 데이터를 가져오는 것이 유리할 것으로 생각할 수 있습니다. 재사용할 데이터를 어떻게 할당하느냐에 따라 a) Weight stationary b) Output stationary c) No local reuse 그리고 d) Row stationary dataflow라고 표현하는데요. 간단히 얘기해서 Weight를 RF에 할당하여 최대한 재사용할지, Activation을 RF에 할당하여 재사용할지에 대한 내용이라고 생각할 수 있습니다. 그렇다면 No local reuse 디자인은 왜 존재하는 것일까요? 항상 재사용하는 것이 유리하지 않나요? 그렇지 않고 일부 케이스에 대해서는 Register file을 없애고 그만큼 하드웨어 면적을 Global Buffer를 확장하는 것이 유리한 경우가 있습니다. 이런 케이스를 No local reuse라고 하며, 대신 PE들 간의 재사용 외에는 Global Buffer를 거쳐야 하므로 효율은 조금 떨어진다는 것을 유추해 볼 수 있습니다.
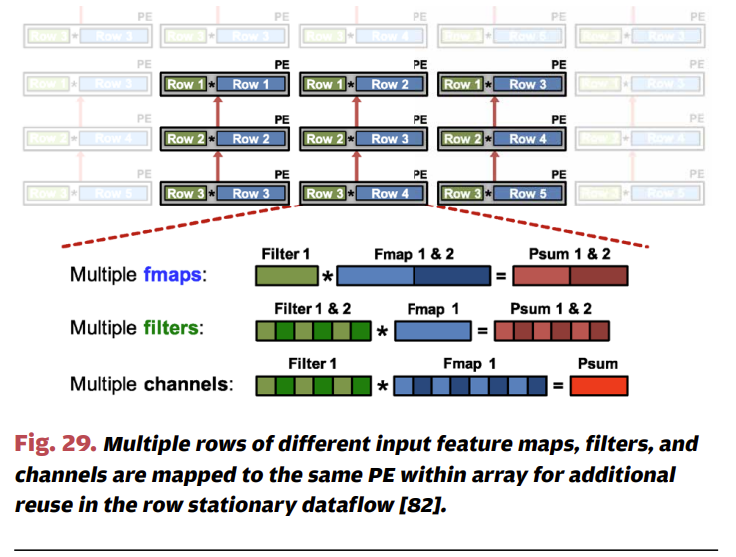
마지막으로 Row stationary dataflow는 Input, Weight 그리고 Partial Sum을 최대한 재사용하는 구조라고 볼 수 있는데요. 위 그림을 보면 Filter (초록색)은 PE들 간에 수평으로 재사용되며, Fmap (파란색)은 Diagonally 하게 재사용, 마지막으로 Partial Sum (붉은색)은 PE들 간에 수직으로 재사용되는 것을 알 수 있습니다.
2. Adapting DNN Accelerators for Transformers
앞에서 가속기의 주 컴포넌트들과 재사용을 어떤 식으로 진행하는지 살펴봤는데요. 눈치채신 분들도 계시겠지만, 이런 가속기의 구조들은 대체로 CNN 네트워크를 잘 가속하기 위해서 최적화된 구조입니다. 다시 말해서 Transformer 네트워크를 효율적으로 추론하기 위해서는 여러 가지 고려 요소들이 필요한데요.
- 메모리 계층별 최적화된 사이즈
- 비선형 연산 (Transformer에는 GELU나 Softmax와 같은 Non-linear 연산들이 존재하죠?)
- Datapath design
- MHA 모듈에 최적화
- End-to-end Transformer 추론에 최적화
- MHA 모듈에 최적화
- MHA 내부 연산을 fusing
- 이런 Fusion은 연산의 중간 결과를 Off-chip 메모리에 갔다올 필요 없이 다음 연산에 활용 가능하므로 효율적이지만 그만큼 유연성은 떨어짐
- End-to-end Transformer 추론에 최적화
- 각 operation들은 분리된 형태이며 General한 MatMul engine을 통해 연산됨
- 그러나 가능한 경우 operation들을 fusion
- MHA 모듈에 최적화하는 케이스와 다르게 graph-level의 dataflow가 하드웨어에 하드코딩되진 않음
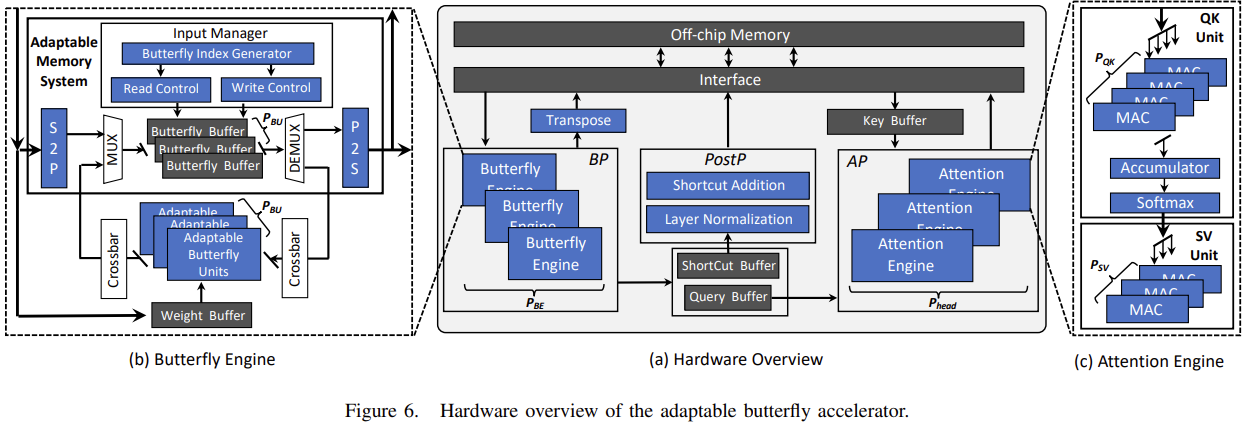
위 그림은 MHA 모듈에 최적화한 하드웨어 디자인을 가져온 것인데요. 우측의 Attention Engine을 보면 QK Unit, Accumulator, Softmax 그리고 SV Unit으로 구성되어 있음을 볼 수 있습니다. 중간의 Post processor를 보면 비선형 연산 중 하나인 Layer Normalization을 처리할 컴포넌트가 따로 있는 것 역시 확인할 수 있네요
3. Analytical Modelling
이런 하드웨어 디자인을 위해서는 어떤 부분이 병목인지, Runtime behavior에 대한 estimation 확인이 필요한데요. 실제 하드웨어에서 이런 작업을 바로 할 수 있다면 좋겠지만, 매우 어렵거나 어떨 때는 불가능한 예도 있습니다. 따라서 일종의 시뮬레이션인 Analytical Modelling을 통해서 병목을 찾을 수 있는데요. 해당 논문에서는 Gemmini 구조를 기반으로 한 수치적 모델링을 보여주고 있습니다.
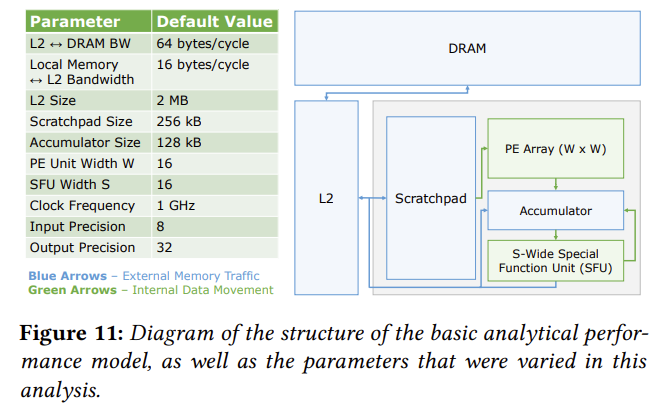
위 그림과 같이 로컬 메모리, Matrix Multiplication이 가능한 PE Array, 그리고 외부 메모리 (DRAM) 등을 확인할 수 있습니다.
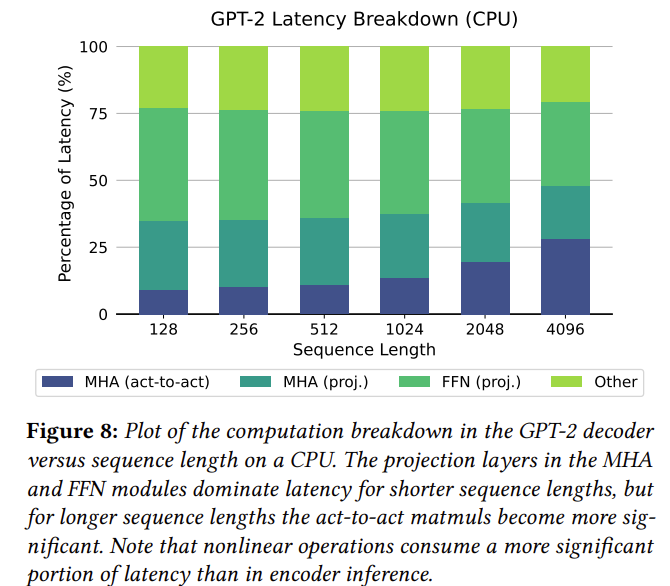

그렇다면 이런 수치적 모델링이 도움이 되는지 얘기를 해야 할 것 같은데요. 다행히도 논문에서는 실제 하드웨어(CPU)에서 GPT-2 모델의 Latency와 Analytic Model을 통해서 계산한 GPT-2 모델의 Latency를 보여주고 있고, Sequence 길이가 커짐에 따른 전반적인 추세는 유사한 것을 위 2개 Figure를 통해서 알 수 있습니다. 그 밖에도 더 정확한 추정을 위해서 하드웨어에 대한 정보를 Analytic Modelling 시 추가할 수 있습니다. 가령, Local scratchpad의 크기를 초과하는 경우 Tiling이 필요하다면 DRAM to L2 memory 트래픽을 수치 모델링에 포함해야겠죠?
4. Case Study: Building a Transformer Acceleartor
앞에서 얘기한 내용들을 기반으로, ResNet50과 같은 CNN 모델에 최적화된 가속기로부터 Transformer 추론에 최적화된 디자인을 결정하는 사고 흐름을 케이스 스터디로 진행해 보려고 합니다. 우선 시작 지점의 설정은 다음과 같습니다
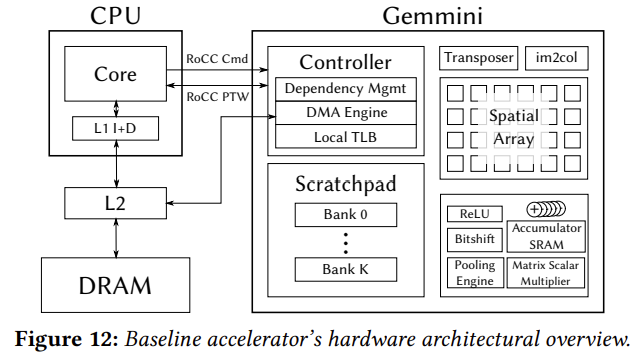
- 행렬곱은 16x16의 systolic array로 이뤄지며 weight stationary
- INT8 weight와 input은 256kb의 local scratchpad에 저장됨
- 32bit partial sum은 SRAM에 저장됨
- Fallback은 Local scratchpad -> L2 Cache -> DRAM 계층으로 진행
- Tiling은 Host CPU이 관여
- ReLU와 Pooling을 Native Support
- LayerNorm이나 GELU와 같은 Transformer specific한 기능은 제공되지 않으며, 따라서 이런 연산은 CPU로 offload됨
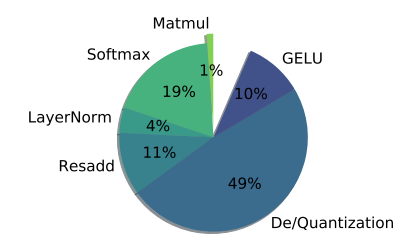

위와 같은 베이스라인을 기준으로 성능 벤치마크를 진행했을 때 위와 같은 다이어그램과 도표의 결과를 얻을 수 있었습니다. 표에 의하면 거의 99% FLOPs (MHA, FFN)가 MatMul로 발생하는데, 다이어그램의 실제로 Inference 시 연산 유형별 차지하는 비율의 값은 그것과는 거리가 꽤 있어 보입니다. 즉 LayerNorm, GELU, Softmax와 같은 비선형 연산이 병목임을 알 수 있고, 이는 Host CPU로 offload를 해야 하기 때문임을 짐작할 수 있습니다. 그 외에도 Arithmetic Intensity를 통해 Memory 계층 역시 Transformer 추론 시에는 추가적인 튜닝이 필요함을 알 수 있습니다.
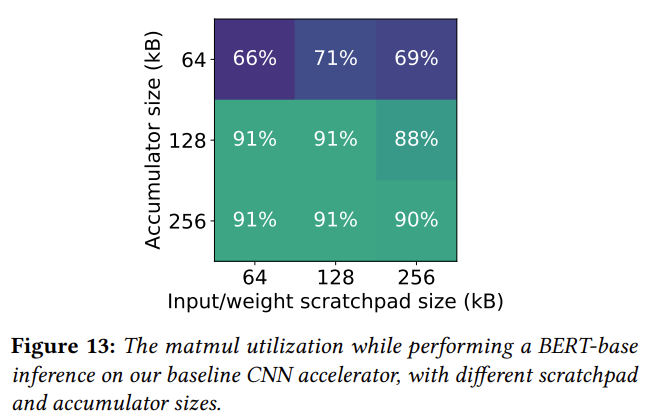
우리는 트랜스포머 구조에서 QK 행렬곱시 입력 query와 key 행렬은 l x d/h이지만 출력은 l x l 임을 알고 있습니다. 즉, partial sum을 저장할 공간을 늘리는 것이 유리하다는 것을 알 수 있는데요. 논문에서는 input/weight scratchpad를 256kb에서 64kb로 대신 partial sum accumulator를 64kb에서 256kb로 조절한 것만으로도 36%의 행렬곱 latency 개선을 얻을 수 있었다고 서술하고 있습니다.
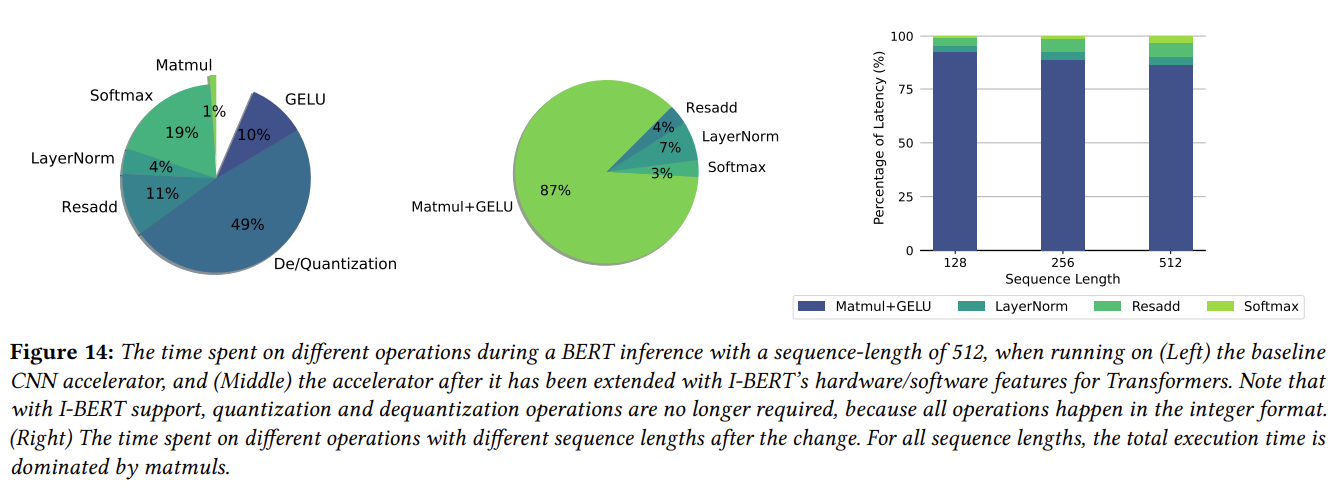
마지막으로는 Hardware-Software Co-design에 관해서 얘기하면서 Transformer Accelerator 디자인을 마무리하는데요. 앞서 말한 FP 비선형 연산들이 CPU로 offload 되어야 하고 그 과정에서 quantization/dequantization이 병목의 원인이 됩니다. 따라서 이런 FP 연산을 Integer polynomal approximation을 통해서 Integer 연산으로 변경하면서 39.6x의 추론 성능의 개선을 만들 수 있었다고 합니다. 위 figure의 중간 다이어그램처럼 이런 최적화 후에는 FLOPs 테이블의 결과처럼 이제는 MatMul이 dominant한 비중을 가지며, Quantization/Dequantization 역시 필요 없어진 것을 알 수 있습니다.
Summary
해당 논문의 Hardware Design 챕터를 통해서 우리는 딥러닝 가속기의 주 컴포넌트에 대해서 알 수 있었고, 추론 최적화를 위해서 메모리 계층이 어떤 식으로 구성되며 어떻게 재사용을 할 수 있을지 다뤄보았습니다. 기존 CNN에 최적화된 가속기를 수치 모델링과 실제 케이스 스터디를 통해 어떤 식으로 Transformer에 최적화된 형태로 개선할 수 있을지 알아볼 수 있었습니다.
References
- Full Stack Optimization of Transformer Inference: a Survey
- Hardware and software optimizations for accelerating deep neural networks: Survey of current trends, challenges, and
the road ahead - Efficient Processing of Deep Neural Networks: A Tutorial and Survey
- Adaptable
butterfly accelerator for attention-based nns via hardware and algorithm codesign - I-bert: Integer-only bert quantization